A neural network represents features as directions in its activation space.
Ideally, each feature gets its own orthogonal direction.
This way, features don't interfere with each other since the dot product between any two orthogonal vectors is zero, and if those feature directions span the space, you can decompose any vector as a weighted sum of them.
But orthogonality means that in dimensions, you can have at most mutually orthogonal feature vectors.
A really interesting phenomenon is the notion of superposition, where models represent more features than they have dimensions by allowing all features to be almost orthogonal to each other.
This introduces a small amount of interference between features and there's no longer a unique feature decomposition for every vector, but models can express far more features as a result.
I figured it would be worthwhile to try approximating just how many features can be represented this way in dimensions.
More precisely, given and a small , what is the maximum size of a set such that:
for all , and
for all distinct .
Recall the two equivalent formulations of the dot product: algebraically, , and geometrically, where is the angle between and . For unit vectors, this simplifies to . Since , condition 2 says that every pair of vectors is almost orthogonal. For we recover ordinary orthogonality and . In practice we're interested in the regime .
We'll sketch a probabilistic lower bound that is exponential in .
The idea is to build greedily: pick vectors one at a time, and argue that at each step there remains a nonzero measure set of directions that are still nearly orthogonal to all previously chosen vectors.
To sample a uniformly random direction in , draw each coordinate independently from the standard normal distribution and normalize the result. This works because the joint distribution is spherically symmetric: the probability density is proportional to , which depends only on , so all directions are equally likely.
Suppose we fix a unit vector and sample a random unit vector . Without loss of generality, let , so that , the first coordinate of . If is our unnormalized Gaussian vector, then
Since each has mean , by the law of large numbers for large , so . Since , the dot product behaves like a random variable, and the probability that exceeds is approximately
The standard Gaussian tail bound gives for , so
Now we build one vector at a time. Suppose we've already chosen , and we want to add a -th vector. For each existing , the "forbidden region", where a random unit vector would have , has probability at most .
By the union bound, the probability that falls in any forbidden region is at most
As long as this is less than , there exists a valid choice for . This holds whenever
so we can greedily build a set of at least
mutually -almost-orthogonal unit vectors. This is exponential in for any fixed despite being a very weak lower bound.
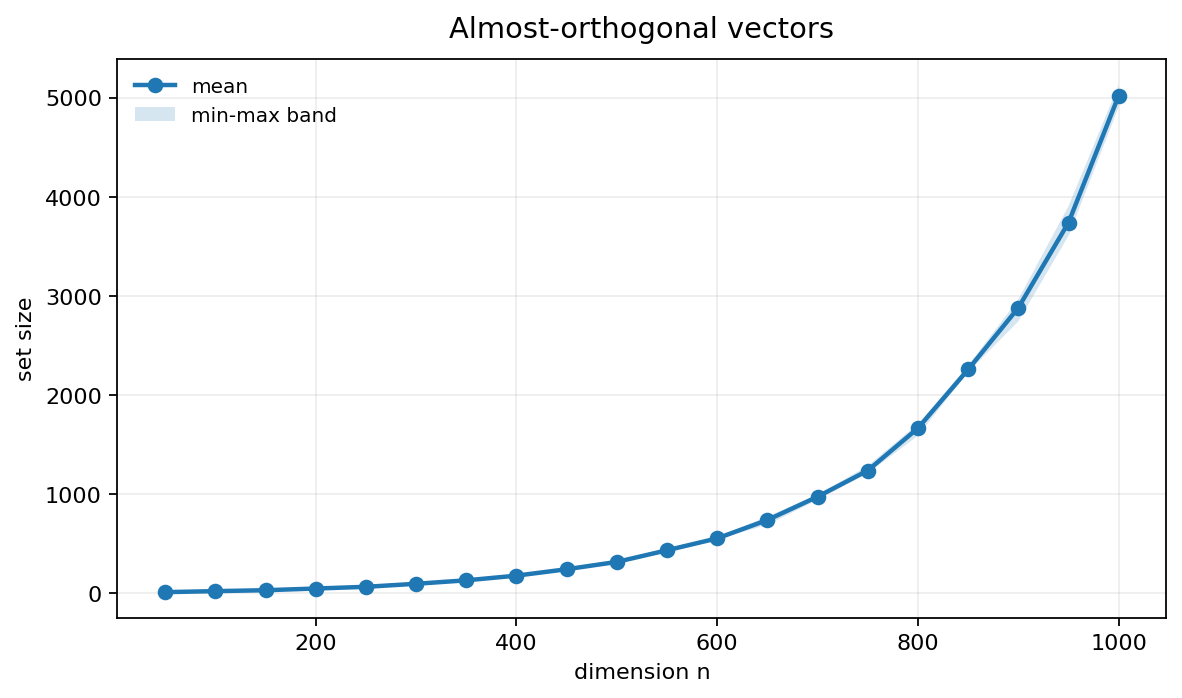
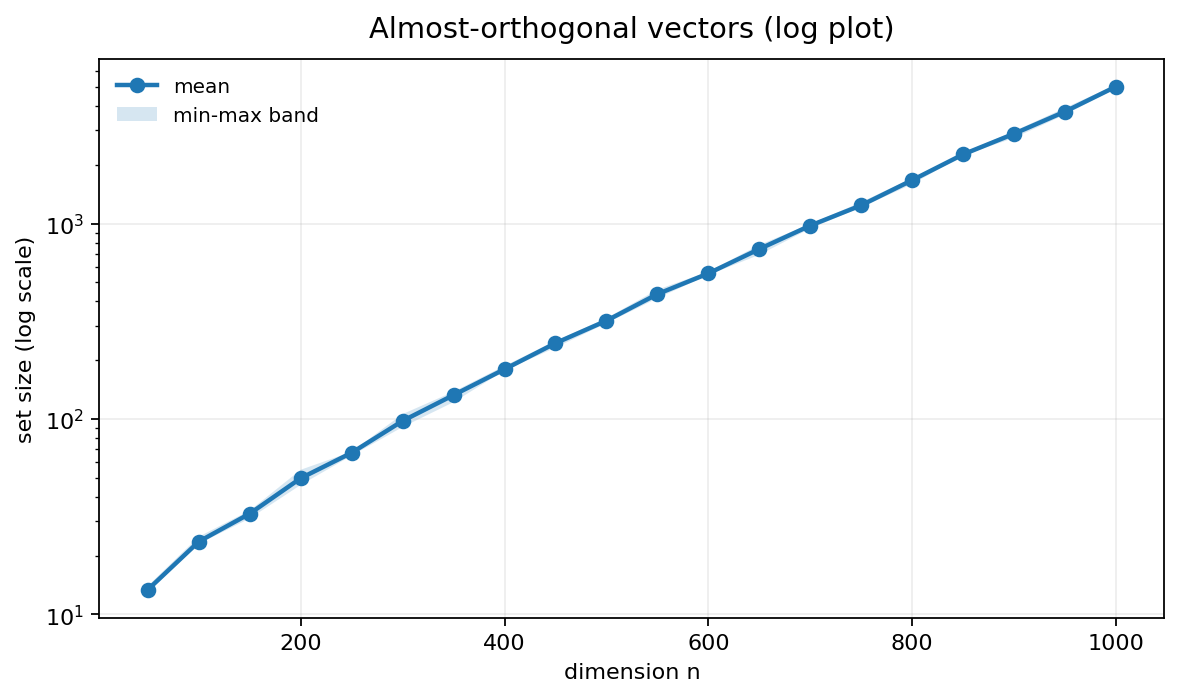
To verify this experimentally, I ran the greedy construction with : sample a random unit vector, add it to if it is -almost-orthogonal to every existing vector, and stop once many random vectors in a row fail to satisfy this condition. Each dimension was tested over 5 independent trials. The code is on GitHub.
The log-scale plot confirms the exponential growth with the points almost forming a straight line here.
In practice, I expect machine learning models to pack almost orthogonal vectors much more tightly, and many features won't be fully independent, so there should be far more features.