Machine Learning Isn't Magic; It's Just Optimization
Rather than listing machine learning models and techniques, I want to start from first principles and build up the idea of machine learning. Some problems seem intractable in computer science, like programmatically determining whether an image shows a dog. If you knew nothing about machine learning, it'd be hard to imagine where you'd even start.
On the other hand, there are far simpler problems we do know how to solve. So it makes sense to start with a simple problem we can solve and gradually make it harder until it resembles the difficult problem we care about.
Optimizing a Quadratic Polynomial
Suppose we're running a business and want to maximize our revenue from a product.
We notice that if we price the product at
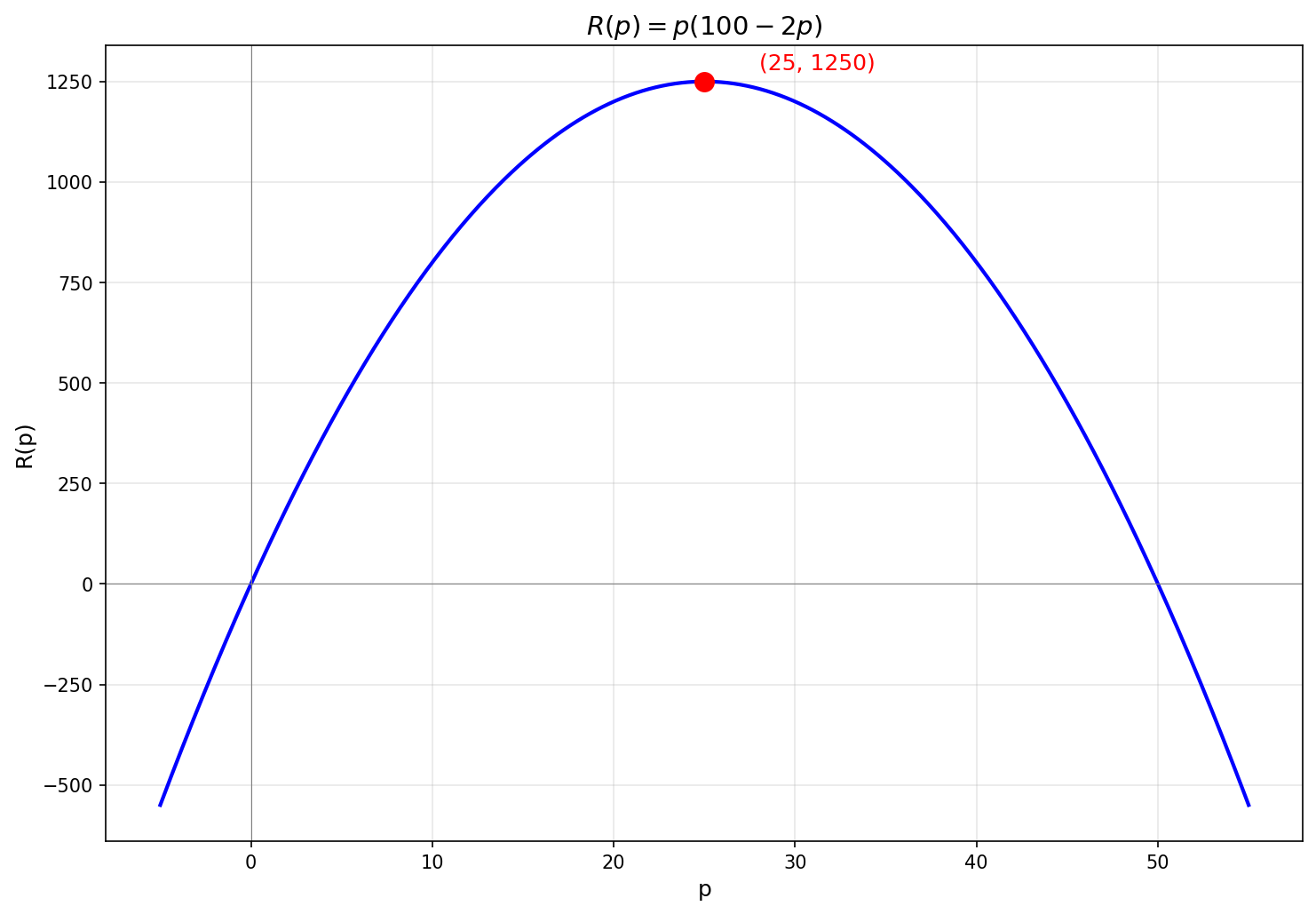
There are multiple approaches we could use to maximize a simple quadratic polynomial.
One way is to complete the square and rewrite
A more general-purpose approach is to find the critical points by setting the derivative to
A still more general approach, when we can't solve
The simplest approach is to just use the sign of the derivative:
Each step moves
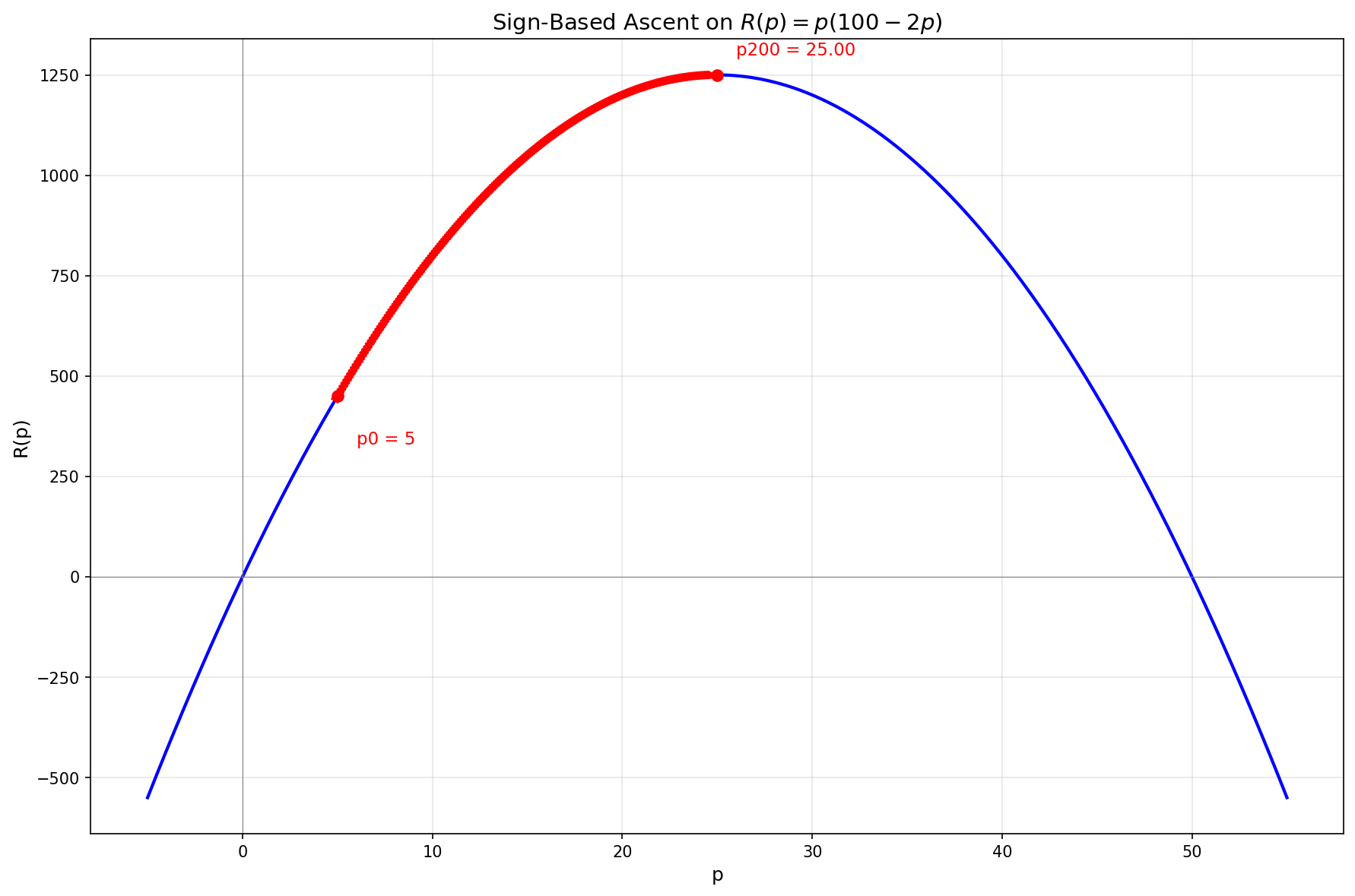
This works, but the fixed step size is a limitation. If the step is too large, we might overshoot the maximum and oscillate around it. If it's too small, convergence is slow. We can do better by also using the magnitude of the derivative: taking larger steps when we're far from the peak (where the slope is steep), and smaller steps as we approach it (where the slope flattens).
This gives us gradient ascent with the update rule
Now the steps naturally get smaller as we approach the peak, allowing for both fast initial progress and precise convergence.
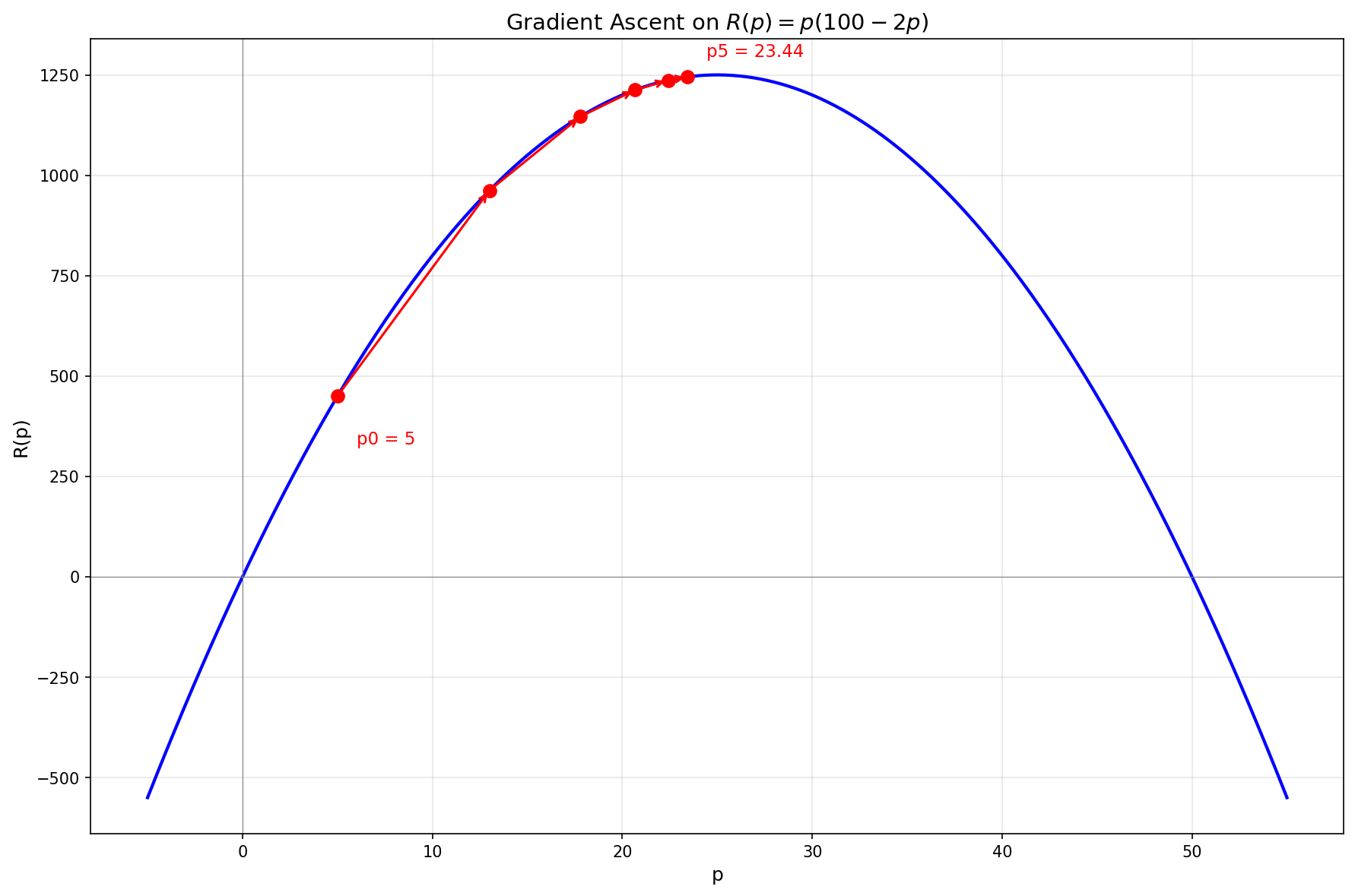
Now let's move on to a more complex function.
Optimizing a Single-Variable Function
The previous example was a quadratic, where we could solve
Consider
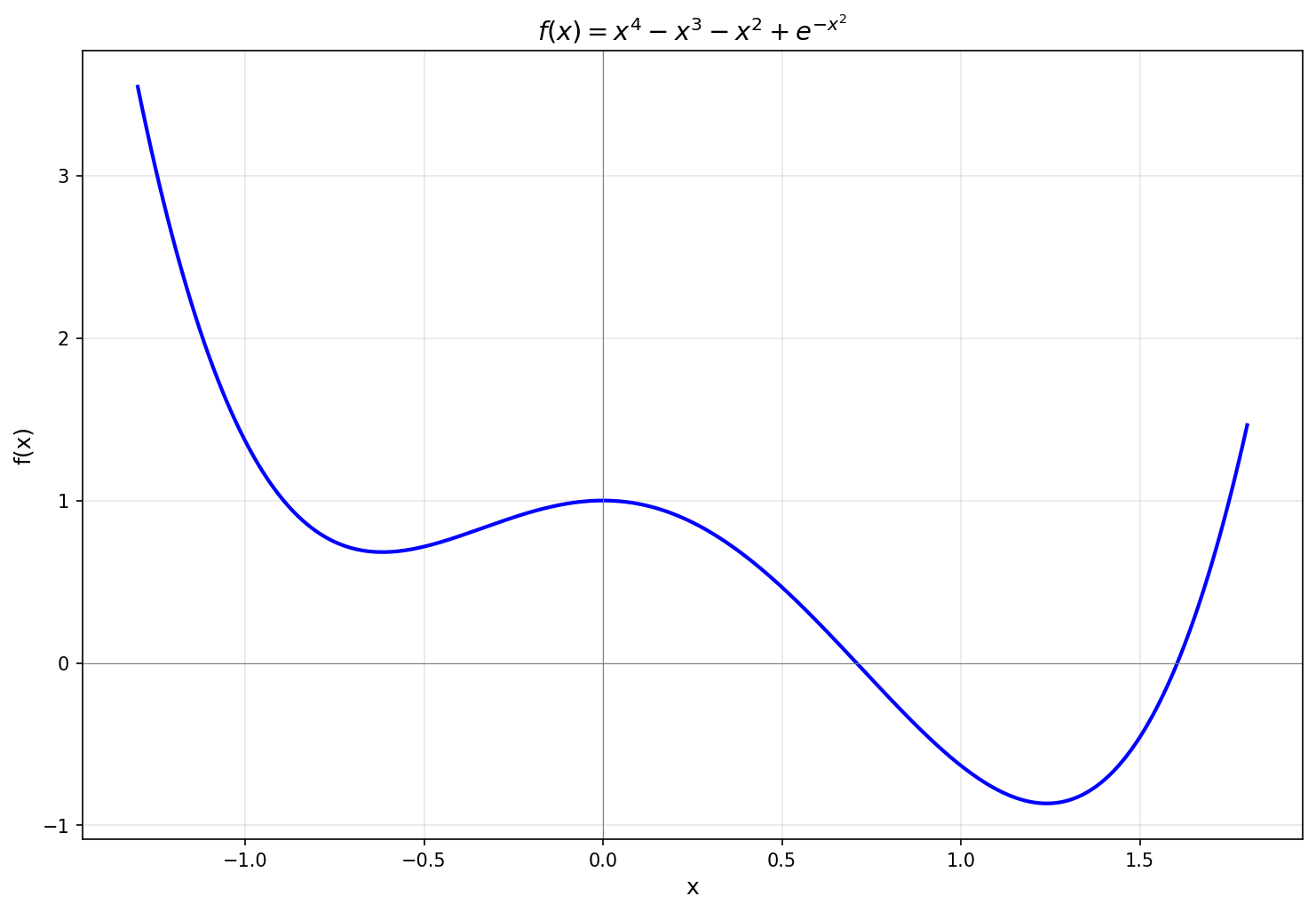
This function has two local minima, one near
After a few more steps,
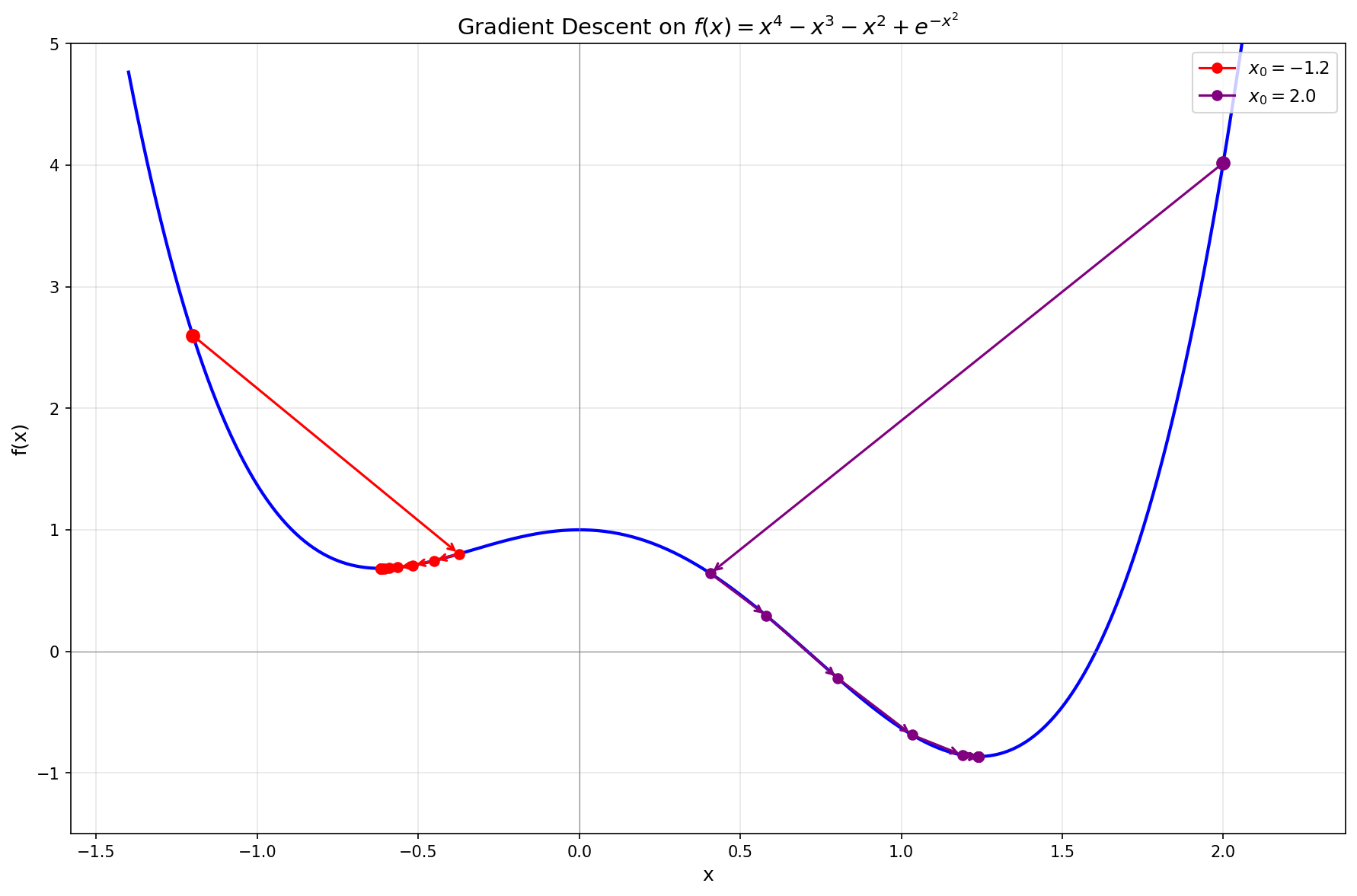
The plot shows two different starting points. Starting from
Optimizing a Two-Variable Function
Now let's add another variable. Consider
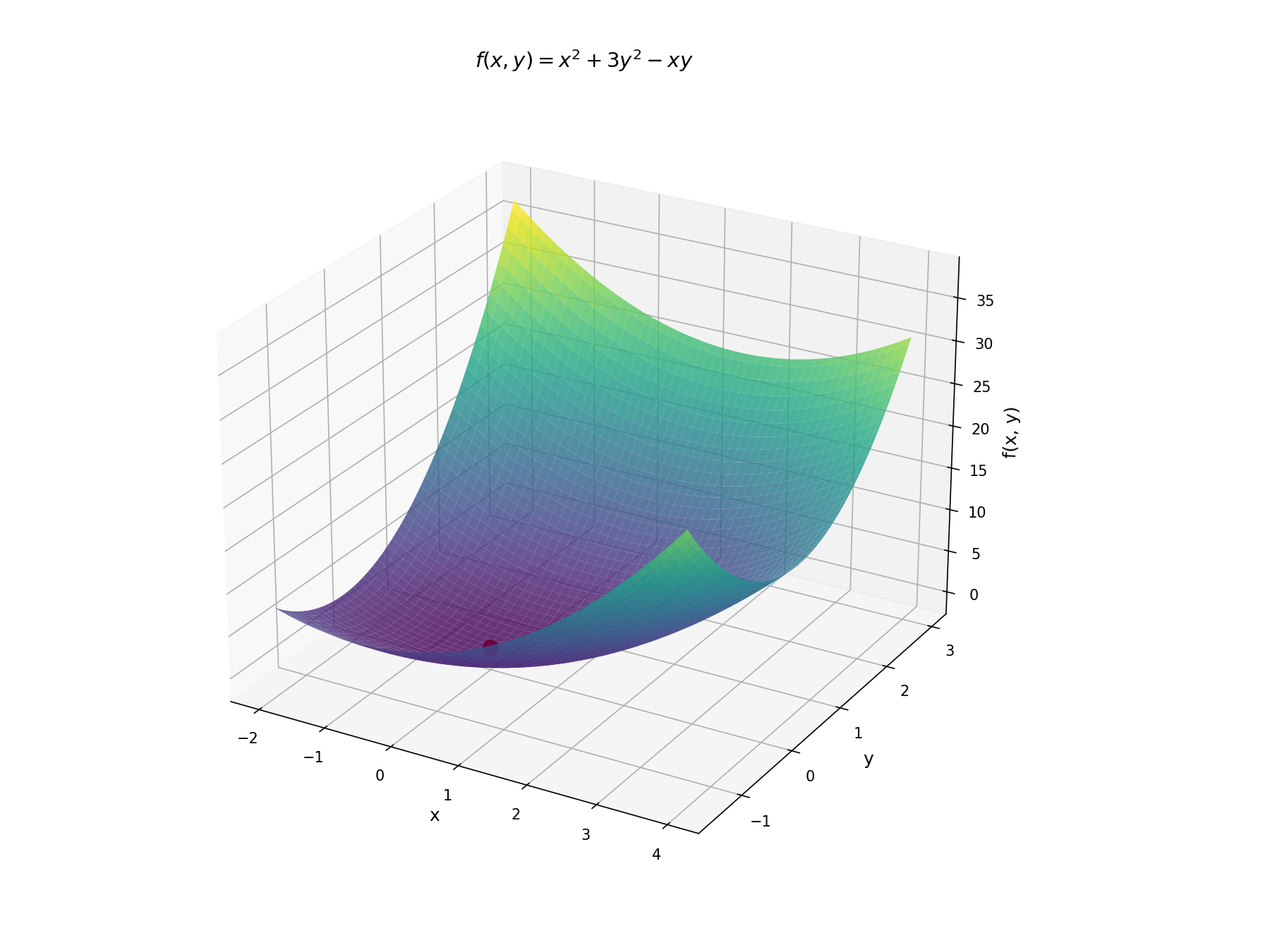
In the single-variable case, we minimized
Together, those partial derivatives form a vector called the gradient:
The gradient points in the direction of increasing
Starting from
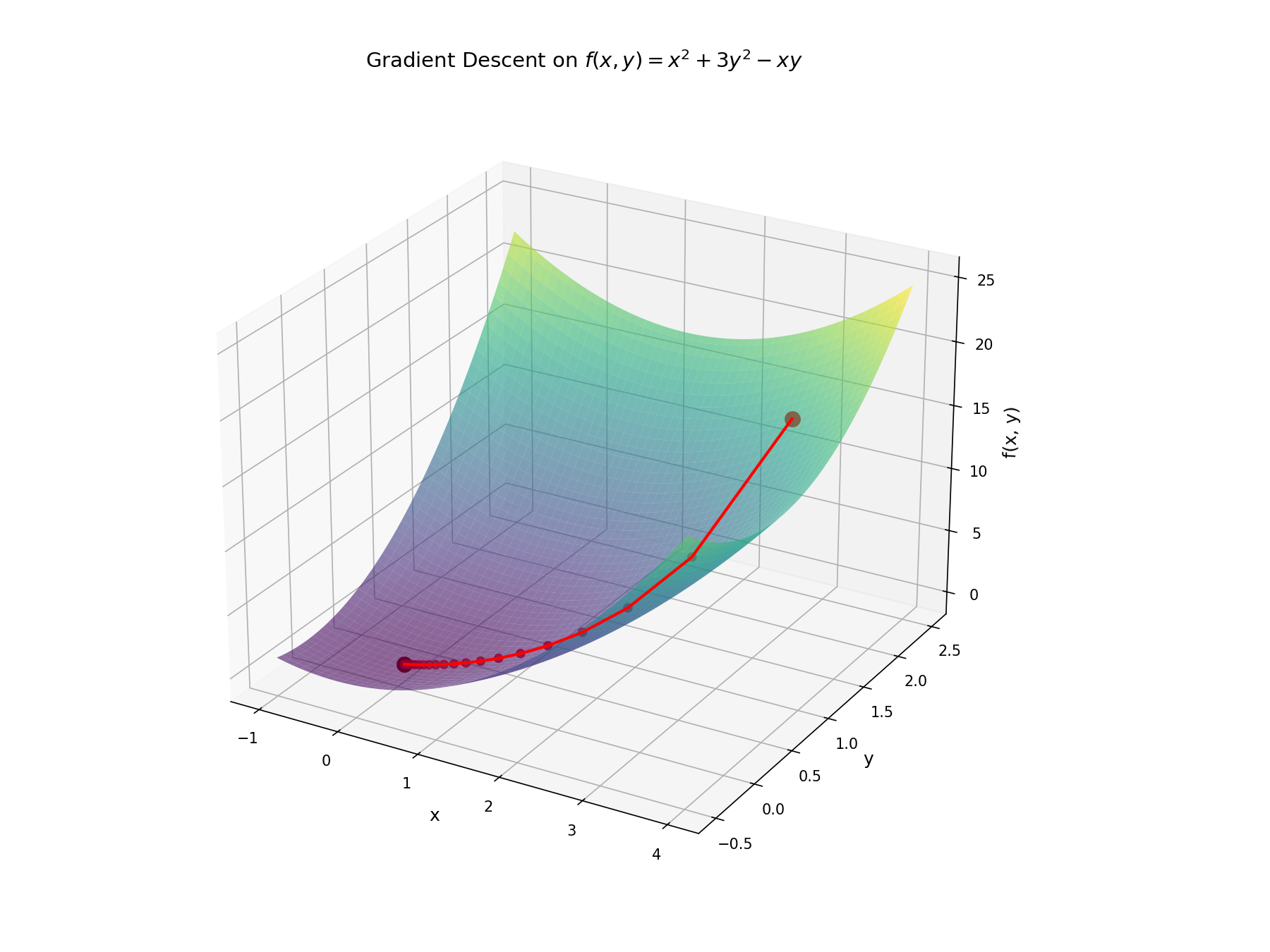
Notice that the path doesn't head straight toward the minimum; it curves because the function is steeper in the
Nothing fundamentally changed from the single-variable case. We're still computing a derivative and stepping opposite to it. The only difference is that our derivative is now a vector.
In one dimension, there are only two directions to move, and only one decreases the function locally. In two dimensions, there are infinitely many descent directions, so in principle there are many update rules we could use, such as changing one variable at a time. So what's special about the gradient vector?
If we fix the length of a small update step
Creating a Simple Model
Now that we have some tools, let's go back to the original problem of programmatically identifying whether an image shows a dog.
Mathematically, we want to find a function
What kind of function could
Now we need to determine what parameters give us the function we want.
We already know how to minimize functions with gradient descent, so we need to turn "find parameters that make
The function
Every term in this sum is zero when the prediction is correct and positive otherwise, so
Of course, this objective is intractable in practice since we can't enumerate every possible image. Instead, we collect a training dataset of
This is called the loss function.
It takes the neural network's parameters and returns a single number measuring how poorly the model performs on the training data.
Minimizing it is structurally the same problem as the ones above.
We compute
The idea behind machine learning with neural networks follows directly from optimization. We define a function that measures error, and minimize it with gradient descent. There's no new mathematical machinery beyond what we've already built up.
Of course, there are plenty of open questions I haven't addressed here. How do we make a model generalize well with limited training data? How do we make training work well when the loss landscape is non-convex and poorly conditioned? How do we choose the network architecture, the optimizer, or the learning rate?