K-Means Clustering Convergence
Suppose you're studying a collection of stars and have measured each one's brightness and temperature. When you plot these measurements, you notice that the stars aren't spread uniformly; they seem to form a few distinct clumps. You'd like an algorithm to automatically identify these groups, but no one has labelled which group each star belongs to. You just have raw measurements and want to discover natural groupings within them.
This is the problem of clustering, where given unlabelled data points, we want to find groups of similar points. It comes up everywhere: grouping stars by type, segmenting genes with similar expression patterns, compressing images by grouping similar pixels, and more.
So how do we find good clusters? In the previous post, we minimized functions using gradient descent, where the fundamental principle behind the gradient update is to take a small step that locally decreases the function. Naturally, it makes sense to do something similar here: construct a function where minimizing it produces good clusters, and then minimize it. This is what k-means clustering does.
In k-means, each cluster is represented by a point in the same space as the data called its center. The center doesn't have to be one of the data points; it's a free parameter that the algorithm can move around. The function k-means minimizes is the total squared distance from each point to its assigned cluster's center:
Unlike neural networks with continuous parameters that we can optimize with gradient descent, this function depends on discrete cluster assignments, so it isn't differentiable with respect to them. Therefore, we need to consider how the function can be locally decreased. There are two kinds of local moves: change a point's assigned cluster, or move the center of some cluster. The former is a discrete change, while the latter is a continuous change where gradient descent can be used.
The best local change to a point's assignment is to reassign it to the cluster whose center is closest, so we can reassign all points' clusters in this manner.
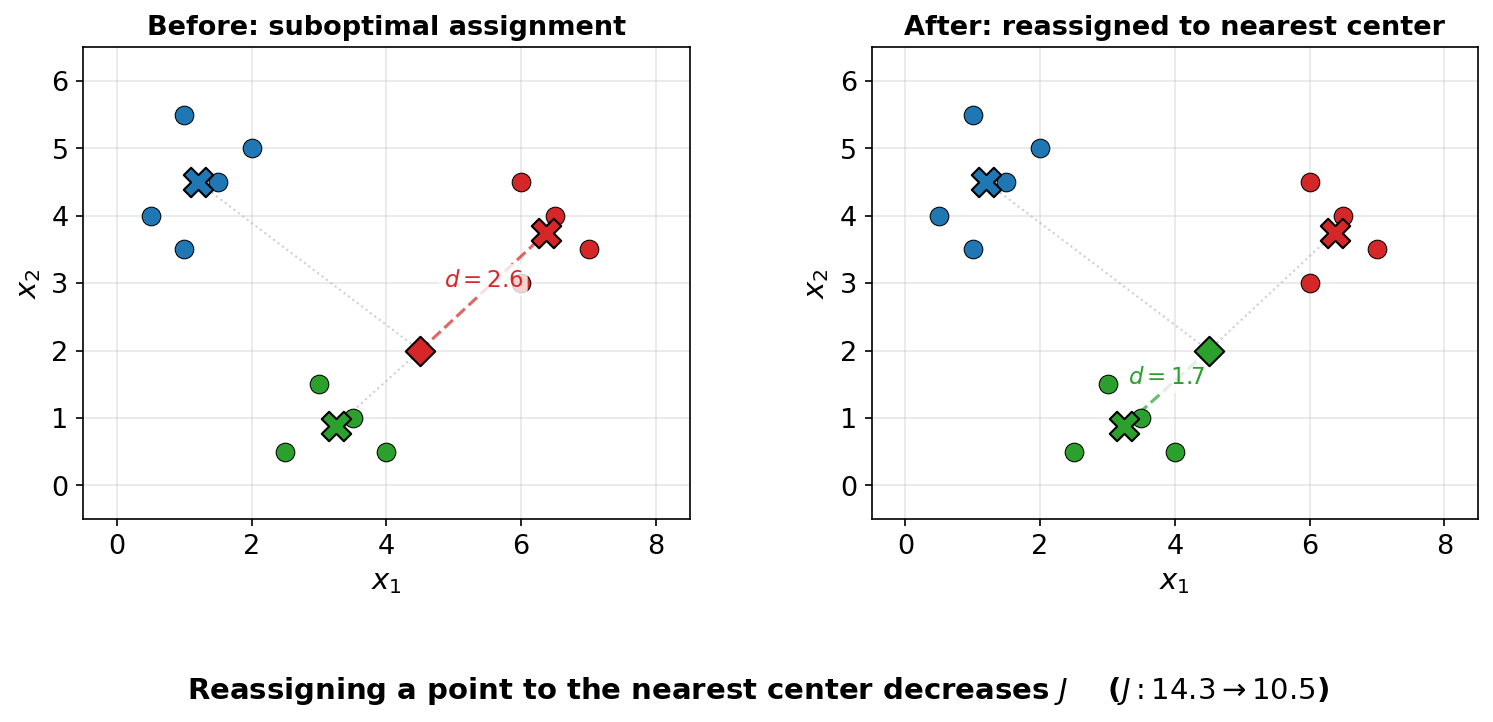
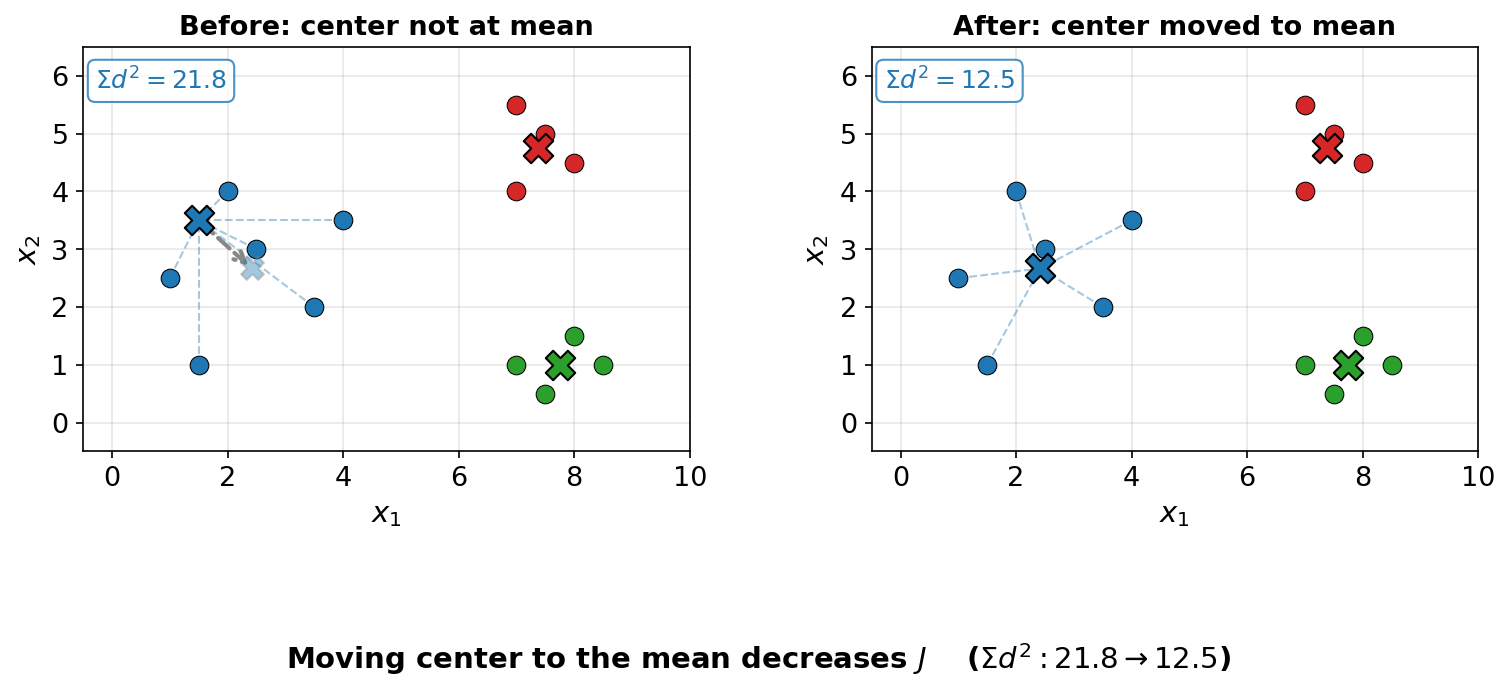
The best way to move a cluster's center would ordinarily be a gradient descent step, but since the function is a simple quadratic polynomial, we can jump directly to the optimal center.
This turns out to be the mean of all points assigned to the corresponding cluster.
To see why, consider a single cluster with points
Thus, the k-means clustering procedure boils down to alternating between these two local changes until neither changes anything.
This procedure necessarily converges because the function is nonnegative, each step cannot increase it, and whenever the assignments change
To conclude, k-means clustering isn't some arbitrary procedure. It follows the same pattern as gradient descent, where we define an objective, then iteratively decrease it by making local improvements. And just like gradient descent, making local improvements doesn't guarantee reaching the global minimum. K-means can get stuck in a local minimum depending on where the cluster centers are initialized.